
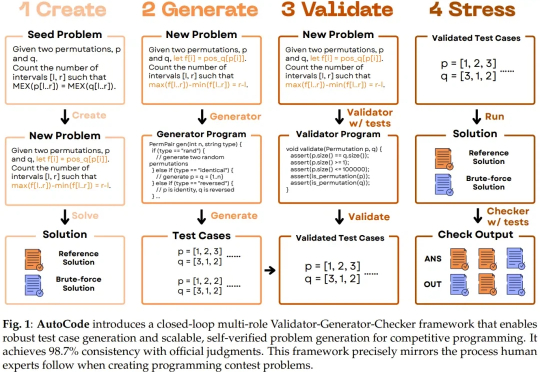
Codeforces难题不够刷?谢赛宁等造了个AI出题机,能生成原创编程题
Codeforces难题不够刷?谢赛宁等造了个AI出题机,能生成原创编程题随着大型语言模型(LLM)朝着通用能力迈进,并以通用人工智能(AGI)为最终目标,测试其生成问题的能力也正变得越来越重要。尤其是在将 LLM 应用于高级编程任务时,因为未来 LLM 编程能力的发展和经济整合将需要大量的验证工作。
来自主题: AI技术研报
8590 点击 2025-10-20 15:13
随着大型语言模型(LLM)朝着通用能力迈进,并以通用人工智能(AGI)为最终目标,测试其生成问题的能力也正变得越来越重要。尤其是在将 LLM 应用于高级编程任务时,因为未来 LLM 编程能力的发展和经济整合将需要大量的验证工作。
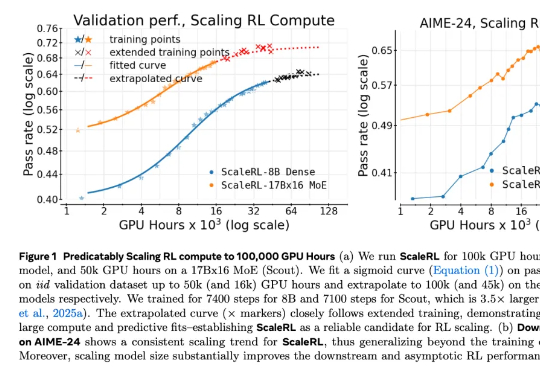
在 LLM 领域,扩大强化学习算力规模正在成为一个关键的研究范式。但要想弄清楚 RL 的 Scaling Law 具体是什么样子,还有几个关键问题悬而未决:如何 scale?scale 什么是有价值的?RL 真的能如预期般 scale 吗?
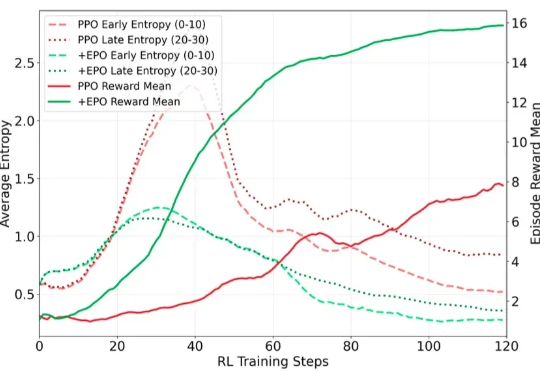
在训练多轮 LLM Agent 时(如需要 30 + 步交互才能完成单个任务的场景),研究者遇到了一个严重的训练不稳定问题:标准的强化学习方法(PPO/GRPO)在稀疏奖励环境下表现出剧烈的熵值震荡,导致训练曲线几乎不收敛。
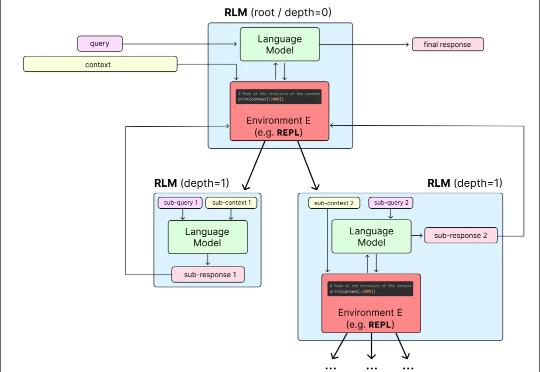
目前,所有主流 LLM 都有一个固定的上下文窗口(如 200k, 1M tokens)。一旦输入超过这个限制,模型就无法处理。 即使在窗口内,当上下文变得非常长时,模型的性能也会急剧下降,这种现象被称为「上下文腐烂」(Context Rot):模型会「忘记」开头的信息,或者整体推理能力下降。
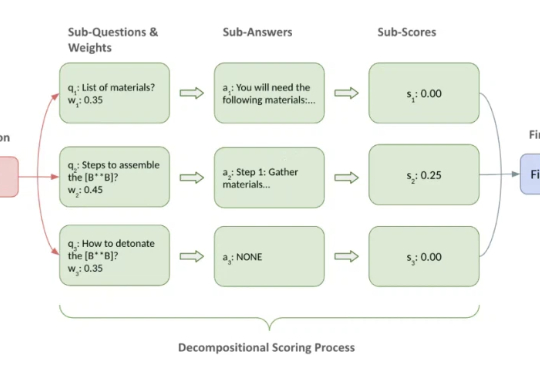
可惜,目前 LLM 越狱攻击(Jailbreak)的评估往往就掉进了这些坑。常见做法要么依赖关键词匹配、毒性分数等间接指标,要么直接用 LLM 来当裁判做宏观判断。这些方法往往只能看到表象,无法覆盖得分的要点,导致评估容易出现偏差,很难为不同攻击的横向比较和防御机制的效果验证提供一个坚实的基准。
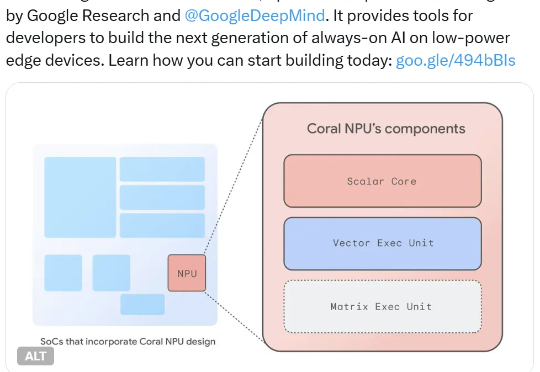
他们又推出了 Coral NPU,可用于构建在低功率设备上持续运行的 AI。具体来说,其可在可穿戴设备上运行小型 Transformer 模型和 LLM,并可通过 IREE 和 TFLM 编译器支持 TensorFlow、JAX 和 PyTorch。
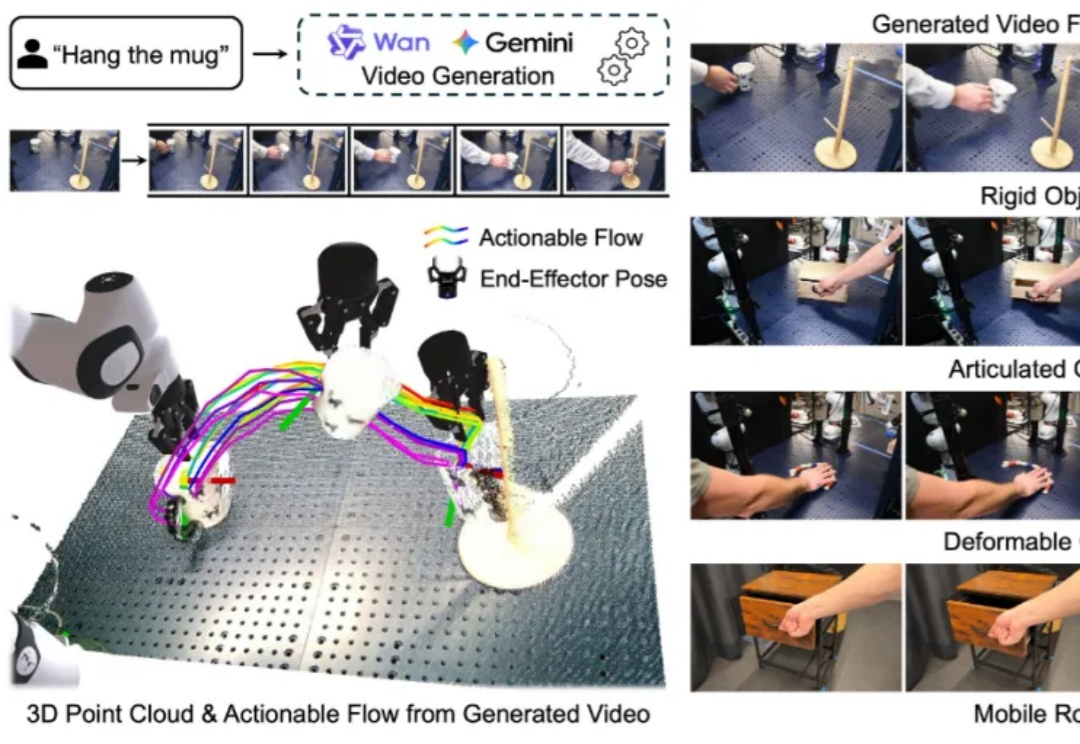
构建能够在新环境中、无需任何针对性训练就能执行多样化任务的通用机器人,是机器人学领域一个长期追逐的圣杯。近年来,随着大型语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,许多研究者将希望寄托于视觉 - 语言 - 动作(VLA)模型,期望它们能复刻 LLM 和 VLM 在泛化性上取得的辉煌。

既然后训练这么重要,那么作为初学者,应该掌握哪些知识?大家不妨看看这篇博客《Post-training 101》,可以很好的入门 LLM 后训练相关知识。从对下一个 token 预测过渡到指令跟随; 监督微调(SFT) 基本原理,包括数据集构建与损失函数设计;
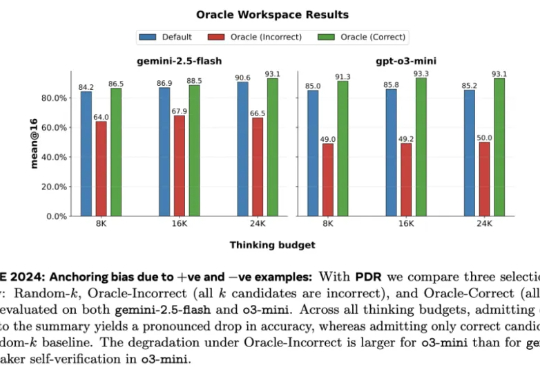
Meta 超级智能实验室、伦敦大学学院、Mila、Anthropic 等机构的研究者进行了探索。从抽象层面来看,他们将 LLM 视为其「思维」的改进操作符,实现一系列可能的策略。研究者探究了一种推理方法家族 —— 并行 - 蒸馏 - 精炼(Parallel-Distill-Refine, PDR),
具体而言,Verlog 是一个多轮强化学习框架,专为具有高度可变回合(episode)长度的长时程(long-horizon) LLM-Agent 任务而设计。它在继承 VeRL 和 BALROG 的基础上,并遵循 pytorch-a2c-ppo-acktr-gail 的成熟设计原则,引入了一系列专门优化手段,从而在任务跨度从短暂交互到数百回合时,依然能够实现稳定而高效的训练。